
EP-5 :Apache Spark - A Tech Deep Dive - Part 1
Beginners Guide to Apache Spark ( PySpark ) - Part 1

Welcome to the episode 5 of “About SWE Weekly” : A Weekly newsletter designed to stay up-to-date on the latest trend in software engineering, covering tech stacks and case studies from SWE world !
This episode will be a tech Deep dive on Apache Spark and will come in multiple episodes, this being the first and dedicated for Beginners. Sit tight as this is going to be one long, interesting story ! We will be covering everything you need to know to get started with spark, and provide you a roadmap to enhance your technical skillset of this technology.
Just a heads-up : This post will mainly deal with theory to get started with spark !
Introduction to Apache Spark :
Apache Spark is an open-source, distributed computing system designed for processing and analyzing large datasets. Spark was introduced after Hadoop and MapReduce as a faster and more flexible alternative for big data processing.
One of the main limitations of MapReduce was its disk-based storage system, which incurred significant overhead in reading and writing data to disk after each Map and Reduce phase. Spark, on the other hand, introduced an in-memory computing model, allowing data to be stored and processed in memory, which significantly improved the processing speed.
Additionally, Spark provided a more versatile and expressive programming model compared to MapReduce. It provides a unified analytics engine that supports various data processing tasks, including batch processing (Spark SQL), real-time streaming (Spark Streaming) , machine learning (MLlib), and graph processing (GraphX) . Spark supports a variety of common languages (Python, Java, Scala, and R) . Spark's architecture was designed to be more modular and extensible, allowing for seamless integration with other big data technologies.

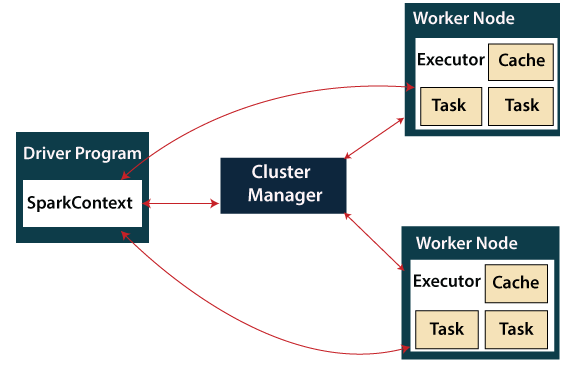
⭐ Spark architecture consists of four components :
Spark driver (Master): The driver program divides the spark application into tasks and schedules them for execution on the cluster. It creates the SparkContext, which is the entry point for interacting with Spark.
Executor (Worker Process) : Executors are worker processes responsible for executing the tasks assigned by the driver program. They are launched on worker nodes in the cluster and are responsible for managing the execution environment, including allocating resources, executing tasks, and storing data in memory or disk.
Cluster administrators : Cluster administrators are responsible for managing the resources and configurations of the Spark cluster. They allocate resources like memory, CPU, and disk space to the Spark application based on the requirements and monitor the cluster for performance and stability. eg, Yarn, Kubernetes
Worker nodes : Worker nodes are the machines in the cluster where the Spark executors run. Worker nodes communicate with the driver program and other worker nodes to exchange data and coordinate the execution of tasks.
⭐ Spark Programs can be executed in 2 modes :
Cluster mode : This mode is typically used for production deployments where the cluster manager handles the resource allocation and management. The Spark application is submitted ( Spark-submit ) to the cluster manager, which then launches the driver program on one of the worker nodes.
Client mode : This mode is commonly used for development and debugging purposes as it allows for easy interaction with the Spark application. In client mode, the driver program runs on the machine from which the Spark application is submitted.

⭐ The Apache Spark architecture consists of two main abstraction layers :
RDD : Spark’s immutable data storage framework, which helps in recomputing data in case of failures. There are two kind of operations for modifying RDDs: Transformations and actions.
a. Transformation : Lazily evaluated ( Chained until Action ) - e.g., join , select
b. Action : Immediately evaluated - e.g., show , collect
Note : The functions given in the example are from Dataframe API which is a layer of abstraction on top of the RDD API to make your life easier. Anyone who has used pandas in python will be familiar with dataframes. Even R language has one!
DAG : It is the Execution plan created by spark for the evaluation of RDD :
Job → Stage → Tasks
a. A job is initiated when an action is called on a DataFrame or RDD .
b. A stage is a group of multiple transformations that is created when wide dependency transformation like groupby or join exist in a job.
This article has more details → article
c. A task is the smallest unit of work in Spark and represents partition. Spark then assigns a task to a single core of the worker node.
Note : Each executor process can have multiple cores ( threads ) which will decide the level of parallelism ( number of total slots )
n (total slots) = n (executors) * n (cores)
⭐ Why is spark Faster ?
Lazy Evaluation
Distributed / Parallel Execution
In-Memory Processing ( RAM )
P.S : Refer a friend and unlock exclusive offers for yourself !
Follow Along :
Here are few ways to install spark:
Easy Deployment of Apache Spark on Local Kubernetes - YouTube
Install PySpark on Google Colab - Super easy
Use helm Charts to install Spark on Kubernetes - Super easy
So, we reached the end of this episode ! Until next time : )