


EP-6 : Delta Lake - A Tech Deep Dive
Beginners Guide to Delta Lake, Lakehouse and Apache Spark .

Welcome to the episode 6 of “About SWE Weekly” : A Weekly newsletter designed to stay up-to-date on the latest trend in software engineering, covering tech stacks and case studies from SWE world !
This episode will be a tech Deep dive on Delta Lake and can be considered as part-2 of Apache Spark series !
Introduction to Delta Lake
Databricks (the company behind Spark) came up with a unique solution that enables ACID transactions over existing Data Lakes which is known as delta Lake . Delta Lake is an open-source storage framework that enables building a Lakehouse architecture with compute engines including Spark, PrestoDB, Flink, Trino, Hive etc.
Data in Delta Lake is stored in Parquet format, thus enables Delta Lake to leverage the efficient compression and encoding schemes that are native to Parquet. Here are some additional features that delta lake provides over parquet :

ACID transactions ensure concurrent DML operations without corruption.
Scalable Metadata handling is achieved through Schema enforcement .
Data versioning helps in data time travel / rollback.
What is Data Lakehouse ?
A lakehouse combines the best elements of data warehouses and data lakes thus excel at both analytical and machine learning workloads. Delta lake is an example for Data lakehouse and is the transactional layer that provides ACID to data lake. Atomicity is achieved by maintaining metadata like location of data, changes made to data, schema of data and the partitions made to data as Transactional Logs .

🧠 Food for thought :
Data Warehouse - Also known as OLAP ( online analytical processing ) and are used for ad-hoc analysis. They are column based RDBMS, hence result in faster queries.
eg. Snowflake
Databases - Also known as OLTP ( online transaction processing ) and are used for read & write of transactions.
eg, Redis , MongoDB , MySQL
Data Lakes - A centralized repository designed to store, process, and secure large amounts of structured, semistructured, and unstructured data. Its highly flexible because it supports schema on read ( apply schema while running queries ) but that’s a disadvantage too as it leads to data swamp if data catalogue is not maintained.
eg, Amazon S3 Storage , Azure Data Lake Storage
Delta Lake - Provides versioned data, ACID transactions, schema enforcement ( schema on write ) for Data lakes .
Here is the diagram of Medallion architecture ( Incremental improvement in structure and quality of data : Raw → Validated → Enriched )
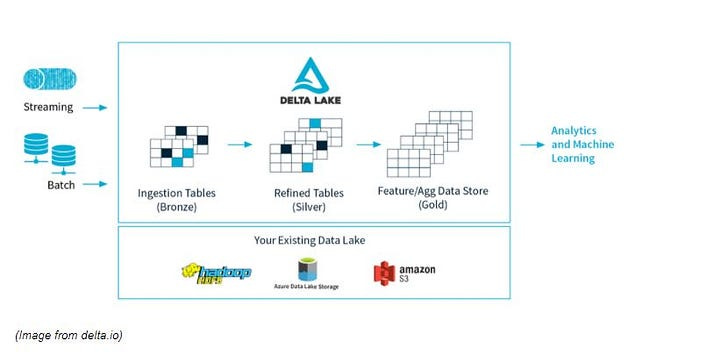
P.S : Refer a friend and unlock exclusive offers for yourself !
How to use Delta Lake with Apache Spark ?
Run Pyspark with delta package interactively : pyspark –packages io.delta:delta-core_2.12:2.4.0
( Here 2.12 is Scala version and 2.4.0 is delta lake version )
In python projects, to include Delta Lakes , add the following lines:
spark = pyspark.sql.SparkSession.builder.appName("MyApp")\
.config("spark.jars.packages", "io.delta:delta-core_2.12:2.4.0")\
.getOrCreate()
from delta.tables import *Note :
Make sure Delta lake version is compatible with Spark version you are using.
Delta Standalone library can be used to read from and write to Delta tables.
API Compatibility :
There are two types of APIs provided by the Delta Lake project.
Direct Java/Scala/Python APIs - The classes and methods documented in the API docs are considered as stable public APIs. All other classes, interfaces, methods that may be directly accessible in code are considered internal, and they are subject to change across releases.
Spark-based APIs - You can read Delta tables through the
DataFrameReader/Writer(i.e.spark.read,df.write,spark.readStreamanddf.writeStream). Options to these APIs will remain stable within a major release of Delta Lake (e.g., 2.x.x).
So, we reached the end of this episode ! Until next time : )