
EP-8 :Zookeeper : A distributed coordination service
Leader Election Using ZooKeeper, Zookeeper Architecture , Zookeeper Use cases

Welcome to the episode 8 of “About SWE Weekly” : A Weekly newsletter designed to stay up-to-date on the latest trend in software engineering, covering tech stacks and case studies from SWE world !
Today, we will be looking at Zookeeper, which is indeed a cornerstone for building robust and scalable distributed systems.
In very simple words, Zookeeper is a central store of key-value using which distributed systems can coordinate. It is used when multiple processes running on multiple machines/nodes need to coordinate in a safe way free from all concurrency related problems. Since it needs to be able to handle the load, Zookeeper itself runs on many machines.
Zookeeper is used for synchronization, locking, maintaining configuration and failover management. It does not suffer from Race Conditions and Dead Locks. This is crucial for many distributed applications where a single system needs to coordinate the actions of others.
Race Condition : When two processes are competing with each other causing data corruption or unexpected results.
Dead Lock : When two processes are waiting for each other directly or indirectly.
Data Model of Zookeeper :
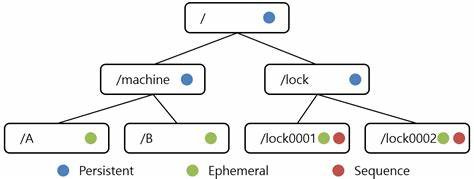
The way you store data in any store is called data model. In case of zookeeper, think of data model as if it is a highly available hierarchical file system. We store data in an entity called znode in JSON format. A znode can store data ( like a file ) or have child znodes ( like a directory )
A znode can only be updated; it does not support append operations. Reads or writes are atomic operations, meaning they will either complete fully or throw an error if they fail. There is no intermediate state, such as being half-written.
There are three types of znodes or nodes: Persistent, Ephemeral and Sequential.
Persistent ZNodes: Provide a clear ordering for determining the leader. Such kind of znodes remain in zookeeper until deleted. This is the default type of znode. To create such node you can use the command: create /name_of_myznode "mydata"
Ephemeral ZNodes: Ensure that when a participant crashes or disconnects, its ZNode is automatically deleted. An ephemeral node can not have children not even ephemeral children.
Sequential ZNodes: Provide a clear ordering for determining the leader. Sequential znode are created with incremental number appended to the provided name.
Leader Election Using ZooKeeper
In distributed system, multiple nodes (servers) work together to achieve a common goal. It sounds cool but its not very easy when it comes to distributed communication. To maintain the balance, and smooth communication between different nodes, one node is chosen as a leader. The leader makes critical decisions and coordinates tasks among the other nodes. The process of choosing a leader is known as Leader Election. It is required because we want a single node accepting modifications from the users and hence consistency across the cluster.
The core concept involves creating ephemeral, sequential ZNodes under a specific path. Each node participating in the election creates a ZNode with a unique identifier under a designated path ( for example: under /election/participant_id_ ). Thus ZooKeeper can be used to track the membership of a group of nodes in a distributed system. ZooKeeper automatically appends a sequence number to the node name.
The node with the lowest sequence number is considered the leader and it acquires the lock. The lock is released only when the session of the leader expires. This is when leader election process is initiated thus enabling a distributed locking mechanism.
ZAB (Zookeeper Atomic Broadcast) is the consensus algorithm that powers ZooKeeper. It's designed to ensure high performance, total order, and fault tolerance in a distributed system.
ZAB operates in three phases:
Phase 1: Leader Election
Initiation: When a leader fails or leaves the cluster, followers initiate a leader election process. Note that the leader must re-certify itself as a leader after a fixed timeout. Failing to do so will cause session expiration and revoke its leadership status.
Voting: Followers exchange information about their view of the system state and elect a new leader. The leader is typically the node with the highest Zxid (ZooKeeper transaction ID).
New Leader: The new leader acquires the lock and broadcasts a new epoch to all followers.
Phase 2: Follower Synchronization
Snapshot: The new leader sends a snapshot of the current system state to followers that are not up-to-date.
Synchronization: Followers load the snapshot and bring their state in sync with the leader.
Phase 3: Atomic Broadcast
Proposal: Clients send update requests to the leader.
Ordering: The leader assigns a sequence number to each request and proposes it to followers.
Commit: Once a majority of followers acknowledge the proposal, the leader commits the update.
Delivery: The leader and followers apply the committed update to their state.
Zookeeper Architecture :
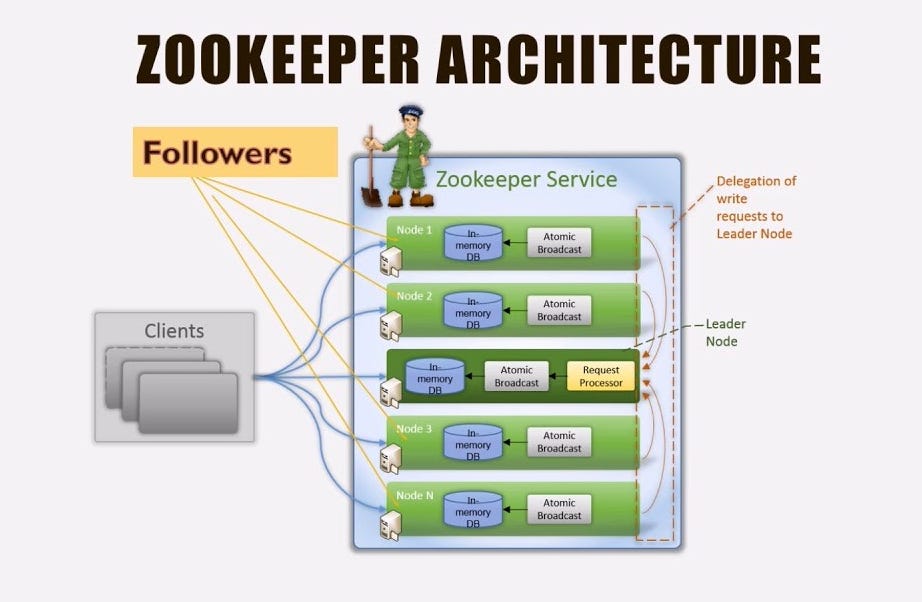
Zookeeper can run in two modes: Standalone and Replicated.
In standalone mode, it is just running on one machine and for practical purposes we do not use stanalone mode. This is only for testing purposes as it doesn't have high availability.
In production environments and in all practical use cases, the replicated mode is used. In replicated mode, zookeeper runs on a cluster of machine which is called ensemble. Basically, zookeeper servers are installed on all of the machines in the cluster. Each zookeeper server is informed about all of the machines/nodes in the ensemble. A leader is elected as detailed above.
Any request from user for writing, modification or deletion of data is redirected to leader by followers. So, there is always a single machine on which modifications are being accepted. The request to read data is catered by all of the machines.
Once leader has accepted a change from user, leader broadcasts the update to the followers - the other machines. This broadcasts and synchronization might take time and hence for some time some of the followers might be providing older data. That is why zookeeper provides eventual consistency not strict consistency.
Why Use ZooKeeper for Strong Consistency?
ZooKeeper actually provides sequential consistency, which is a strong consistency model, but not as strong as linearizability.
Sequential consistency guarantees that the operations of each client appear to execute atomically and in order. However, the order of operations between different clients is not guaranteed.
Linearizability is the strongest consistency model. It guarantees that operations appear to execute atomically and in a specific order as if they were executed on a single process.
While ZooKeeper doesn't provide linearizability, it offers several features that make it suitable for many scenarios requiring strong consistency:
Total Order: Updates are processed in the same order by all servers, ensuring consistency.
Quorum-based Decisions: ZooKeeper uses quorums to make decisions, preventing inconsistencies in case of failures.
Leader-centric Architecture: A single leader ensures a consistent order of updates.
Sync Operation: Clients can use the
sync()operation to guarantee that their writes are visible to all servers before proceeding.
ZooKeeper is a great choice for distributed systems that require:
Reliable coordination: Leader election, distributed locks, configuration management
High availability: Fault tolerance and automatic recovery
Strong consistency: Sequential consistency is sufficient for many applications
However, if your application absolutely requires linearizability, ZooKeeper might not be the best fit. In such cases, you might consider using a database with strong linearizability guarantees. examples include :
High-frequency, low-latency transactions: For applications demanding extreme performance and consistency, a dedicated transactional database might be more suitable.
Complex data models: If your data has complex relationships and requires ACID transactions, a relational database might be a better fit.